
Introduction
This tutorial teaches the fundamentals of SQL (Structured Query Language) by using Python to build applications that interact with a relational database (PostgreSQL).
This blog post is Part 1 of the "Learn SQL with Python" series:
- SQL Fundamentals
- Filtering, Sorting, and Grouping
- Joins and Set Operators
The source code for this tutorial can be found on GitLab: https://gitlab.com/patkennedy79/learn_sql. There are separate folders for each of the 3 parts of this tutorial.
Relational Databases
A crucial aspect of software development is managing and organizing vast amounts of information. Relational databases play a pivotal role in this landscape, providing a structured and efficient means of storing, retrieving, and managing data.
Relational Database Management System
A Relational Database Management System (RDBMS) is a software framework designed to efficiently store, manage, and retrieve structured data in a relational database.
Examples of Popular RDBMSs:
- PostgreSQL: An open-source RDBMS known for its robust features, extensibility, and support for advanced data types.
- MySQL: A widely-used open-source RDBMS, recognized for its speed, reliability, and ease of use.
- Oracle Database: A commercial RDBMS offering a comprehensive suite of features, ideal for large-scale enterprise applications.
- Microsoft SQL Server: A popular RDBMS developed by Microsoft, known for its integration with the Microsoft ecosystem and comprehensive feature set.
RDBMSs form the backbone of countless applications, ranging from simple web applications to complex enterprise systems.
In this tutorial, PostgreSQL will be used, as it is a great choice for applications ranging from small-scale projects to large enterprises.
Key Components of Relational Databases
At its core, a relational database is a type of database that stores and organizes data in tables, each consisting of rows and columns. The relationships between these tables are defined based on common fields, creating a structured and interconnected data model.
The key components of a relational database include:
- Tables: fundamental building blocks of a relational database. Each table represents a specific entity, such as customers, products, or orders.
- Columns: define the attributes or properties of the entity. Each field contains a specific piece of information about the entity represented by the record. In a "customers" table, columns would include attributes like "customer_id," "name," "email," and "address."
- Records: a unique occurrence of a particular entity (also called a "row") that the table is designed to capture. For example, in a "customers" table, each record would represent information about a specific customer.
- Primary Key: a unique identifier for each record in a table. This primary key ensures that no records within the same table have identical values in the key field, facilitating easy and unambiguous identification.
- Relationships: The relationships between tables are established through keys, specifically primary and foreign keys. A primary key uniquely identifies each record in a table, while foreign keys create links between tables.
- SQL: SQL serves as the universal language for interacting with relational databases. It provides a standardized syntax for defining, querying, and manipulating data.
PostgreSQL Database
Running a PostgreSQL Database using Docker
In this tutorial, a PostgreSQL database will be running in a Docker container and we'll be developing Python applications to interact with this relational database.
If you don't have Docker installed on your computer, install the applicable version (macOs, Windows, Linux) from https://www.docker.com/products/docker-desktop/.
In a new terminal window, check that Docker is installed and running:
$ docker --version
Docker version 24.0.7, build afdd53b
Pull down the latest Postgres image:
$ docker pull postgres
Start a new container running a Postgres server and creating a new database:
$ docker run --name learn-sql-with-python -e POSTGRES_PASSWORD=tomatoes -e POSTGRES_DB=learn-sql -p 5432:5432 -d postgres
Here are all the options used:
--name- name of the Postgres container-e- environment variable applicable to the Postgres container:- 'POSTGRES_PASSWORD' - database password (required)
- 'POSTGRES_DB' - database name that gets created when the container starts (optional, default database created is
postgres)
-p- port mapping of the host port on your computer that maps to the PostgreSQL container port inside the container-d- run in daemon mode (container keeps running in the background)
To check that the PostgreSQL container is running:
$ docker ps
CONTAINER ID IMAGE ... STATUS PORTS NAMES
9d5784e74bea postgres ... Up 2 seconds 0.0.0.0:5432->5432/tcp learn-sql-with-python
To stop the PostgreSQL container, copy the "Container ID" from the docker ps command:
$ docker stop <CONTAINER ID>
If you are interested in learning more about how to use Docker, I would recommend reading the following blog post from TestDriven.io: Docker for Beginners.
Virtual Environment
Before creating a Python application to interact with the PostgreSQL database running in the Docker container that was just started, a virtual environment should be created. Virtual environments create isolated environments for each of your Python projects, so that each project can have its unique dependencies (imported Python packages) and utilize a specific version of the Python interpreter.
If you don't have Python installed on your computer, install the applicable version (macOs, Windows, Linux) from https://www.python.org/downloads/.
Start by creating a new directory and changing into that directory:
$ mkdir learn-sql
$ cd learn-sql
Python has a built-in module called venv that can be used for creating virtual environments.
Run the following command to create a new virtual environment:
$ python3 -m venv venv
This command creates a new directory called "venv", which contains the following items:
- Python interpreter (Python 3.12 in this case)
- Scripts for activating and deactivating the virtual environment
It will also store the Python packages that we install for this project throughout this course.
To start using the virtual environment, it needs to be activated:
$ source venv/bin/activate
(venv) $
After activating, the virtual environment (venv) will be displayed on your command prompt, to the left of the prompt.
Since the virtual environment is active, running the python command will run the Python 3 version of the interpreter
(which is stored within your virtual environment itself):
(venv) $ python --version
Python 3.12.1
With the virtual environment created and activated, it's time to start installing the Python packages that you need
using pip.
Install psycopg2 for interacting with the PostgreSQL database and prettytable for printing the SQL query results:
(venv) $ pip install psycopg2 prettytable
It's a good idea to save the installed packages (including version numbers) to a file called requirements.txt.
Here's the command that I like to run (works with macOS and Linux) to save the package information:
(venv)$ pip freeze | grep "psycopg2==" >> requirements.txt
(venv)$ pip freeze | grep "prettytable==" >> requirements.txt
The requirements.txt file should now look like:
(venv)$ cat requirements.txt
psycopg2==2.9.9
prettytable==3.9.0
Connect to a PostgreSQL database
Now it's time to write some Python code!
Create a new file in the part1 folder called part1.py. Then, in your text editor of choice, add the following content:
import psycopg2
# ----------------------
# Database Configuration
# ----------------------
DATABASE_HOST = '127.0.0.1'
DATABASE_NAME = 'learn-sql'
DATABASE_USER = 'postgres'
DATABASE_PASSWORD = 'tomatoes'
# --------
# Database
# --------
class Database:
"""Class for interacting with a PostgreSQL database."""
def __init__(self, host: str, name: str, user: str, password: str):
self.database_host = host
self.database_name = name
self.database_user = user
self.database_password = password
self.db_connection = None
self.db_cursor = None
def open_database_connection(self):
"""Connect to the PostgreSQL database."""
print(f'Connecting to the PostgreSQL database ({self.database_name})...')
# The `db_connection` object encapsulates a database session. It is used to:
# 1. create a new cursor object
# 2. terminate database transactions using either:
# - commit() - success condition where database updates are saved (persist)
# - rollback() - failure condition where database updates are discarded
self.db_connection = psycopg2.connect(
host=self.database_host,
database=self.database_name,
user=self.database_user,
password=self.database_password
)
# The `db_cursor` object allows the following interactions with the database:
# 1. send SQL commands to the database using `execute()` or `executemany()`
# 2. retrieve data from the database using `fetchone()`, `fetchmany()`, or `fetchall()`
self.db_cursor = self.db_connection.cursor()
def print_database_version(self):
"""Print the database version information."""
self.db_cursor.execute('SELECT version();')
print(f'PostgreSQL database version: {self.db_cursor.fetchone()}')
def close_database_connection(self):
"""Close the database connection."""
print(f'\nClosing connection to the PostgreSQL database ({self.database_name}).')
self.db_cursor.close()
self.db_connection.close()
def commit(self):
"""Commit the changes to the database to make them persistent."""
self.db_connection.commit()
def rollback(self):
"""Discard the changes to the database to revert to the previous state."""
self.db_connection.rollback()
if __name__ == '__main__':
db = Database(DATABASE_HOST, DATABASE_NAME, DATABASE_USER, DATABASE_PASSWORD)
db.open_database_connection()
db.print_database_version()
db.close_database_connection()
The Database class is responsible for the following:
open_database_connection()- opening a connection to the PostgreSQL databaseprint_database_version()- printing the version of the PostgreSQL databaseclose_database_connection()- closing the connection to the PostgreSQL databasecommit()- save the changes to the database to persist the datarollback()- discard changes to the database
To create a connection to a PostgreSQL database using psycopg2, the host (using the localhost identifier
of '127.0.0.1'), name, user, and password are needed:
self.db_connection = psycopg2.connect(
host=self.database_host,
database=self.database_name,
user=self.database_user,
password=self.database_password
)
The arguments being passed in should match up with the parameters used for creating the PostgreSQL Docker container.
Here's what the output should look like when you run this Python script:
$ python part1/part1.py
Connecting to the PostgreSQL database (learn-sql)...
PostgreSQL database version: ('PostgreSQL 16.0 ...',)
Closing connection to the PostgreSQL database (learn-sql).
The typical workflow when working with a relational database is:
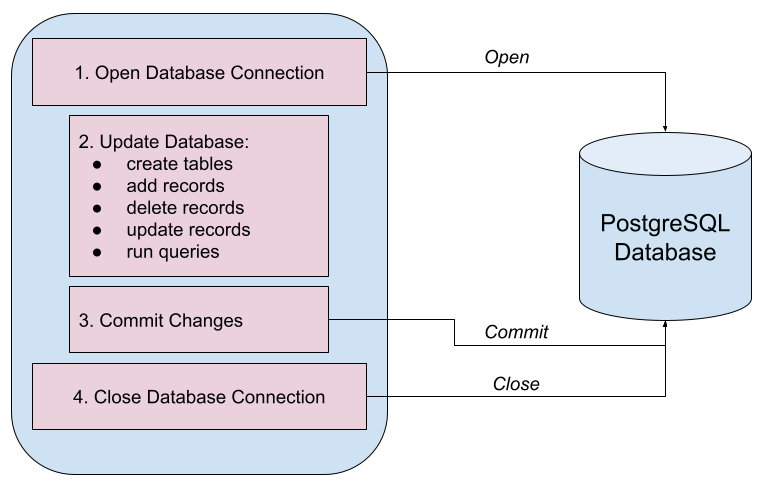
After opening the database connect, updates are made to the database, but these updates occur within a session and do not automatically get saved to the database. After the changes are made, they need to be committed to the database to save the data (i.e. persist the data). The database connection needs to be closed when done working with the database.
NOTE: Multiple occurrences of updating the database (in a session) and then committing the changes can occur while the database connection is open. Always remember to close the database connection at the end!
If any problems occur while updating the session (such as adding a bad record or deleting a record by accident), the session can be rolled back to prevent the changes from actually being stored in the database.
It's very important to always make sure to open and close the database connection properly. Let's make that step automatic...
Context Manager
A context manager in Python is used to automatically handle the setup and teardown phases of a specific operation, such as opening a file, opening a network connection, or opening a database connection.
For opening a database connection, the context manager should automatically handle the opening and closing of the database connection, so that we don't have to manually include these steps (very error prone!).
Expanding on the part1.py example, add a new class for the context manager:
# ---------------
# Context Manager
# ---------------
class DatabaseContextManager:
"""Context Manager for interacting with a PostgreSQL database."""
def __init__(self, host: str, name: str, user: str, password: str):
self.database = Database(host, name, user, password)
def __enter__(self):
self.database.open_database_connection()
return self.database
def __exit__(self, exc_type, exc_val, exc_tb):
self.database.commit()
self.database.close_database_connection()
The DatabaseContextManager class has a __init__() to initialize an instance of the Database class. The setup
(__enter__()) and teardown (__exit__()) steps for the database interaction are defined to open and close the
database connection, respectively.
Now the script execution can be updated to:
if __name__ == '__main__':
with DatabaseContextManager(DATABASE_HOST, DATABASE_NAME, DATABASE_USER, DATABASE_PASSWORD) as db:
db.print_database_version()
The with keyword is used to run statements under the control of the context manager (DatabaseContextManager). When
the block of code within the with statement starts executing, the __enter__() method is called to open the
database connection. After the code within the with statement, the __exit__() method is called to
close the database connection. Now we don't need to remember to open/close the database connection!
Database Schema
Within the PostgreSQL database, we are going to be creating a table for storing the products available at a farmers market. The schema of a database shows the configuration of the entire database:
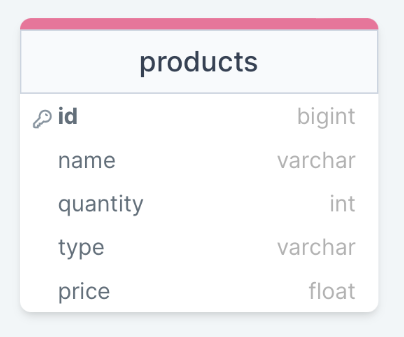
A great resource for creating SQL diagrams is: https://drawsql.app/
For Part 1 (SQL Fundamentals) of this tutorial, we are only working with a single table: products.
Typically, a database table should be specified as a plural to indicate that it will contain multiple records of that entity.
To create a new table in SQL, the CREATE TABLE statement is used:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
....
);
To create the products table:
CREATE TABLE products(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
quantity INT,
type VARCHAR(50),
price FLOAT
);
It's a best practice to end a SQL statement with a semicolon.
In each table, there needs to be a way to uniquely identify each record (i.e. row) in the table, which is the purpose
of the PRIMARY KEY keyword. In the products table, the id field is used to uniquely identify each record in the
table. The AUTO_INCREMENT keyword is also used with the PRIMARY KEY keyword to tell the database to automatically
increment the id field for each record added to the products table.
Let's create a new class for working with the products table:
# --------------
# Database Table
# --------------
class Products:
"""Class for working with the products table in the PostgreSQL database."""
def __init__(self, db_cursor):
self.db_cursor = db_cursor
def create_table_schema(self):
"""Create the schema for the produce table."""
# Create the schema (i.e. columns) for the products table
# NOTE: The keyword SERIAL is used in PostgreSQL for an
# auto-incrementing primary key. In other relational
# database systems, this would be "PRIMARY KEY AUTO_INCREMENT".
self.db_cursor.execute("""
CREATE TABLE products(
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
quantity INT,
type VARCHAR(50),
price FLOAT
);
""")
The Products class will define the SQL commands for working with the products table. The constructor requires
the db_cursor to be passed in, which will come from the database connection created with the context manager above.
SQLite has a confusing approach to support the FLOAT data type. If you are using SQLite for any purpose (testing, development) in your project, it is recommended to use an INT data type that has been multiplied by 100 for storing prices (using two decimal places). This value can then be divided by 100 when read to get the decimal value.
Altering the Table
After creating a table, the SQL statement to add a column to a table is:
ALTER TABLE table_name
ADD column_name data_type;
For example, to add a new 'description' text column to the products table:
ALTER TABLE products
ADD description VARCHAR(255);
When a new column is added to a table, each record will have 'NULL' for that new column:
products:
+----+------------+----------+-----------+-------+-------------+
| id | name | quantity | type | price | description |
+----+------------+----------+-----------+-------+-------------+
| 1 | banana | 30 | fruit | 0.79 | None |
| 2 | cantaloupe | 12 | fruit | 3.49 | None |
| 3 | carrot | 43 | vegetable | 0.39 | None |
| 4 | tomato | 17 | vegetable | 1.19 | None |
+----+------------+----------+-----------+-------+-------------+
We'll learn how to update records in a later section.
Conversely, the SQL statement to delete a column from a table is:
ALTER TABLE table_name
DROP COLUMN existing_column_name;
For example, to delete the 'type' column from the products table:
ALTER TABLE products
DROP COLUMN type;
Deleting a column from a table causes the data stored in the records for that column to be deleted, so this command should be used very carefully.
Let's add methods to the Products class to add and delete columns:
class Products:
...
def add_column(self, column_name: str, column_type: str):
"""Add a new column to the products table."""
self.db_cursor.execute(f"""
ALTER TABLE products
ADD {column_name} {column_type};
""")
def delete_column(self, column_name: str):
"""Delete a column from the products table."""
self.db_cursor.execute(f"""
ALTER TABLE products
DROP COLUMN {column_name};
""")
Database Interactions
The key operations for working with data in a relational database are often referred to as CRUD:
- Create - add new records to a table in the database
- Read - retrieving or querying data from the database records
- Update - modifying existing records in the database
- Delete - removing records from the database
These operations are fundamental to interacting with and managing the information stored in tables.
Create
To add a new record (i.e. row) to a table in a relational database, the SQL statement is:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
To add a new record to the products table:
INSERT INTO products(name, quantity, type, price)
VALUES ('carrots', 20, 'vegetable', 0.39);
Looking at the list of columns that are specified in the first line, it may seem strange that the id field is missing.
This omission is intentional, as we want the database to automatically set the value of the primary key (id).
This SQL statement to add a new record to the products table can be turned into a new method in Products class:
def add_new_record(self, name: str, quantity: int, product_type: str, price_per_unit: float):
"""Add a new record to the products table."""
self.db_cursor.execute(f"""
INSERT INTO products(name, quantity, type, price)
VALUES ('{name}', {quantity}, '{product_type}', {price_per_unit});
""")
Read
To read all the records (i.e. rows) from a table in a relational database, the SQL statement is:
SELECT *
FROM table_name;
The * (wildcard) character means that all columns should be selected from the specified table. Applying this SQL
statement to read all the columns from the products table:
SELECT *
FROM products;
Add a new method in the Products class for reading all the columns in the products table:
def print_all_records(self):
"""Print all the records in the products table."""
self.db_cursor.execute("""
SELECT *
FROM products;
""")
print('\nproducts:')
for row in self.db_cursor.fetchall():
print(row)
First, the db_cursor is used to execute the SQL query (SELECT * FROM products;). Second, the db_cursor is used
to retrieve (fetch) all the results. The fetchall() method returns the results as a list of tuples.
Now that the Products class has methods to add records to the products table and to read all the records in
the products table, update the script to add 4 records to the table, and then read all these records:
if __name__ == '__main__':
with DatabaseContextManager(DATABASE_HOST, DATABASE_NAME, DATABASE_USER, DATABASE_PASSWORD) as db:
db.print_database_version()
# Create the `products` table schema
products = Products(db.db_cursor)
products.create_table_schema()
# Add records to the products table
products.add_new_record('banana', 30, 'fruit', 0.79)
products.add_new_record('cantaloupe', 12, 'fruit', 3.49)
products.add_new_record('carrot', 43, 'vegetable', 0.39)
products.add_new_record('tomato', 17, 'vegetable', 1.19)
products.print_all_records()
Running the script:
(venv) $ python part1c.py
Connecting to the PostgreSQL database (learn-sql)...
PostgreSQL database version: ('PostgreSQL 16.0 ...',)
products:
(1, 'banana', 30, 'fruit', 0.79)
(2, 'cantaloupe', 12, 'fruit', 3.49)
(3, 'carrot', 43, 'vegetable', 0.39)
(4, 'tomato', 17, 'vegetable', 1.19)
Closing connection to the PostgreSQL database (learn-sql).
Printing SQL Query Results
Let's improve on the look of the results from the SQL query by using the prettytable package.
Add a new method to the 'Products' class for printing all the records in the products table using prettyprint:
from prettytable import from_db_cursor
def print_all_records_v2(self):
"""Print all the records in the products table."""
print('\nproducts:')
self.db_cursor.execute("""
SELECT *
FROM products;
""")
table = from_db_cursor(self.db_cursor)
print(table)
Calling print_all_records_v2() displays a nice table of all the records in the products table:
products:
+----+------------+----------+-----------+-------+
| id | name | quantity | type | price |
+----+------------+----------+-----------+-------+
| 1 | banana | 30 | fruit | 0.79 |
| 2 | cantaloupe | 12 | fruit | 3.49 |
| 3 | carrot | 43 | vegetable | 0.39 |
| 4 | tomato | 17 | vegetable | 1.19 |
+----+------------+----------+-----------+-------+
Filtering by ID
In Part II (Filtering, Sorting, and Grouping) of this tutorial, we'll dive into all the powerful statements for filtering query results. For now, let's filter the query results to just return the ID of a specific record:
SELECT id
FROM table_name
WHERE column_name = 'specified_column_name';
For example, to filter the results to find the ID of the record with a name of 'carrot':
SELECT id
FROM products
WHERE name = 'carrot';
Create a generic version of this filtered query by adding a new method in the Products class:
def get_product_id(self, name: str) -> int:
"""Return the ID of the specified product in the products table."""
self.db_cursor.execute(f"""
SELECT id
FROM products
WHERE name = '{name}';
""")
index = self.db_cursor.fetchone()
return index[0] # fetchone() returns a tuple, but only first element is needed
The get_product_id() method takes an argument of name which is used to filter the query results to the records
WHERE the name is this argument. It is assumed that there will only be a single record returned, so the
fetchone() method is used to get the ID of the record.
Here's an example of using the new get_product_id() method:
if __name__ == '__main__':
with DatabaseContextManager(DATABASE_HOST, DATABASE_NAME, DATABASE_USER, DATABASE_PASSWORD) as db:
db.print_database_version()
# Create the `products` table schema
products = Products(db.db_cursor)
products.create_table_schema()
# Add records to the products table
products.add_new_record('banana', 30, 'fruit', 0.79)
products.add_new_record('cantaloupe', 12, 'fruit', 3.49)
products.add_new_record('carrot', 43, 'vegetable', 0.39)
products.add_new_record('tomato', 17, 'vegetable', 1.19)
products.print_all_records()
products.print_all_records_v2()
# Find the ID of the 'carrot' record
print(products.get_product_id('carrot')) # Prints 3
Database Schema
In addition to reading records from a table in the database, the schema for a table can also be read using the SELECT
statement:
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'table_name';
NOTE: the use of
information_schemais specific to PostgreSQL.
This SQL statement introduces the use of WHERE to help filter the query results. We'll dive much more into using
WHERE in Part 2 of this tutorial.
Add a new method to the Products class to view the schema of the products table:
def print_table_schema(self):
"""Print the schema for the products table."""
print('\nproducts table schema:')
self.db_cursor.execute("""
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'products';
""")
table = from_db_cursor(self.db_cursor)
print(table)
The print_table_schema() method will print the structure of the products table:
products table schema:
+-------------+-------------------+
| column_name | data_type |
+-------------+-------------------+
| id | integer |
| quantity | integer |
| price | double precision |
| name | character varying |
| type | character varying |
+-------------+-------------------+
Update
The syntax for updating a record in a table is:
UPDATE table_name
SET column_name = new_value
WHERE id = specified_id;
For example, to update the price of tomatoes (assuming tomatoes have an index of 4):
UPDATE products
SET price = 1.49
WHERE name = 'tomato';
Add a new method to the Products class to update the price of a specific product:
def change_product_price(self, name: str, new_price_per_unit: float):
"""Change the price per unit of the specified record in the products table."""
self.db_cursor.execute(f"""
UPDATE products
SET price = {new_price_per_unit}
WHERE name = '{name}';
""")
Here's an example of using the new change_product_price() method:
if __name__ == '__main__':
with DatabaseContextManager(DATABASE_HOST, DATABASE_NAME, DATABASE_USER, DATABASE_PASSWORD) as db:
db.print_database_version()
# Create the `products` table schema
products = Products(db.db_cursor)
products.create_table_schema()
# Add records to the products table
products.add_new_record('banana', 30, 'fruit', 0.79)
products.add_new_record('cantaloupe', 12, 'fruit', 3.49)
products.add_new_record('carrot', 43, 'vegetable', 0.39)
products.add_new_record('tomato', 17, 'vegetable', 1.19)
products.print_all_records_v2()
# Change the price of tomatoes
products.change_product_price('tomato', 1.56)
products.print_all_records_v2()
Output:
products:
+----+------------+----------+-----------+-------+
| id | name | quantity | type | price |
+----+------------+----------+-----------+-------+
| 1 | banana | 30 | fruit | 0.79 |
| 2 | cantaloupe | 12 | fruit | 3.49 |
| 3 | carrot | 43 | vegetable | 0.39 |
| 4 | tomato | 17 | vegetable | 1.19 |
+----+------------+----------+-----------+-------+
products:
+----+------------+----------+-----------+-------+
| id | name | quantity | type | price |
+----+------------+----------+-----------+-------+
| 1 | banana | 30 | fruit | 0.79 |
| 2 | cantaloupe | 12 | fruit | 3.49 |
| 3 | carrot | 43 | vegetable | 0.39 |
| 4 | tomato | 17 | vegetable | 1.56 | <-- Price updated!
+----+------------+----------+-----------+-------+
Delete
The syntax to delete a record is:
DELETE FROM table_name
WHERE id = specified_id;
For example, to delete the 1st record in the products table:
DELETE FROM products
WHERE id = 1;
Add a new method to the Products class to delete a record based on its ID:
def delete_product(self, index: int):
"""Delete the specified product from in the products table."""
self.db_cursor.execute(f"""
DELETE FROM products
WHERE id = {index};
""")
Here's an example of using the new delete_product() method:
if __name__ == '__main__':
with DatabaseContextManager(DATABASE_HOST, DATABASE_NAME, DATABASE_USER, DATABASE_PASSWORD) as db:
db.print_database_version()
# Create the `products` table schema
products = Products(db.db_cursor)
products.create_table_schema()
# Add records to the products table
products.add_new_record('banana', 30, 'fruit', 0.79)
products.add_new_record('cantaloupe', 12, 'fruit', 3.49)
products.add_new_record('carrot', 43, 'vegetable', 0.39)
products.add_new_record('tomato', 17, 'vegetable', 1.19)
products.print_all_records_v2()
# Delete carrots from the table
carrot_id = products.get_product_id('carrot')
products.delete_product(carrot_id)
products.print_all_records_v2()
Output:
products:
+----+------------+----------+-----------+-------+
| id | name | quantity | type | price |
+----+------------+----------+-----------+-------+
| 1 | banana | 30 | fruit | 0.79 |
| 2 | cantaloupe | 12 | fruit | 3.49 |
| 3 | carrot | 43 | vegetable | 0.39 |
| 4 | tomato | 17 | vegetable | 1.19 |
+----+------------+----------+-----------+-------+
products:
+----+------------+----------+-----------+-------+
| id | name | quantity | type | price |
+----+------------+----------+-----------+-------+
| 1 | banana | 30 | fruit | 0.79 |
| 2 | cantaloupe | 12 | fruit | 3.49 |
| 4 | tomato | 17 | vegetable | 1.19 |
+----+------------+----------+-----------+-------+
Summary
SQL statements learned in this tutorial:
CREATE TABLE- create a new tableALTER TABLE-ADDa new column to a table orDROPan existing column from a tableINSERT INTO- add a new record (i.e. row) to a tableSELECT- read records from a tableWHERE- filter the query results to return specific record(s)UPDATE- update a record(s) in a tableDELETE- delete a record(s) in a table